
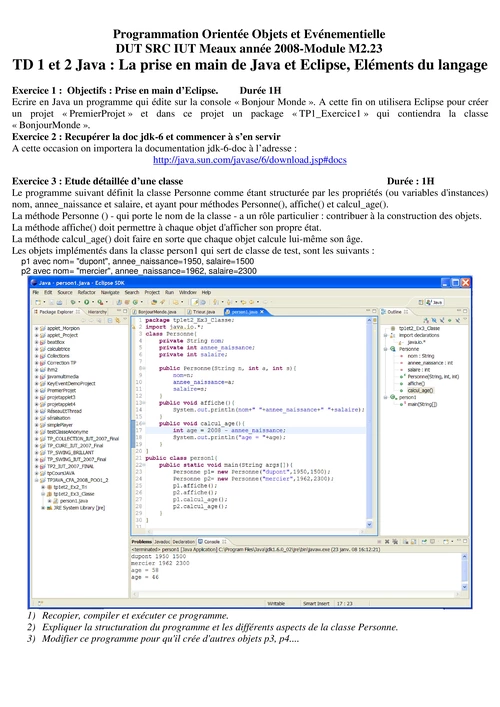
Data-Mining Corrigé Examen 2002/2003 1 Clustering (13 points)
Corrigé Examen 2002/2003. 4eme année. 1 Clustering (13 points). X 1 2 9 12 20. 1. (7 points) K-Means. (a) Appliquez l'algorithme des K-means avec les

TD Clustering_ensta
TD Clustering. ENSTA ParisTech INT-22. Exercice 1 : K-means. Utilisez l'?algorithme du k-means et la distance euclidienne pour regrouper les 8 exemples?
Corrigé
Corrigé. Exercice 1 (10 points) : Soit l'ensemble D des entiers suivants : D= { 2, 5, 8, 10, 11, 18, 20 }. On veut répartir les données de D en trois (3) clusters, en ...

Méthode des K-means - Université Lumière Lyon 2
Algorithme K-Means ? Méthode des centres mobiles. 3. Cas des variables actives qualitatives. 4. Fuzzy C-Means. 5. Classification de variables. 6. Conclusion.

Série N°2 en Fouille de données (Clustering) Exercice n°1 : Soit les ...
En prenant comme centroïdes initiaux les points A B et C, appliquer l'algorithme K-means pour regrouper les points en trois clusters (utiliser la distance de ...

Algorithme K-Moyennes
Clustering ? K-means, Nearest Neighbor and Hierarchical. Exercise 1. K-means clustering. Use the k-means algorithm and Euclidean distance to cluster the

Application de k-means - Dspace
classification non supervisée dont le plus simple est l'algorithme de k-means. Corrige les données pour les différentes échelles et des corrélations dans les

tdr1110 ????? Clustering ou classification avancée
Regroupement (Clustering): construire une collection d' ... Le Clustering est de la classification non ... Heuristic methods: Algorithmes k-means et k-medoids.

Regroupement (clustering)
9 Algorithme des centres mobiles (k means). 49. 10 Consolidation de 16 Exercices. 85 sj : l'écart-type corrigé des valeurs du caractère Xj,. ? le zobs,(j,g) :.

Clustering - Exercices corriges
Clustering : une affaire de distance ?. Etude préliminaire. Valeurs discrètes. Soient les deux individus suivants correspondant à des séquences ADN :.

K-Means
Avantages de l'algorithme : 1) L'algorithme de k-means est très populaire du fait qu'il est très facile à comprendre et à mettre en ?uvre. 2) Sa simplicité

Data Mining
EXERCICE On considère un classifieur binaire linéaire comme défini ci-dessus avec p = 2, X = [0.0 ... 1Des rappels sur ce sujet sont proposés plus loin. 19 ... miner un axe factoriel discriminant (c'est-à-dire le meilleur w) d'après Fisher. 5.

Corrigé de l'Examen de fouille de données
Besse et al., Data Mining et Statistique, Journal de la Société Française de ... Exercice. Deux méthodes de clustering ont conduit aux 2 partitions suivantes :.

Eléments de classification - Christophe Chesneau - CNRS
hiérarchique et les K-means, font partie des méthodes dites de partitionnement et seront ... du sujet de l'étude et des connaissances de l'expérimentateur.

Data Mining - Clustering
9 Algorithme des centres mobiles (k means). 49. 10 Consolidation de l'exercice?, à savoir : sj : l'écart-type corrigé des valeurs du caractère Xj,. ? le zobs :.